【PyTorch】 暂退法(dropout)
文章目录
- 1. 理论介绍
- 2. 实例解析
- 2.1. 实例描述
- 2.2. 代码实现
- 2.2.1. 主要代码
- 2.2.2. 完整代码
- 2.2.3. 输出结果
1. 理论介绍
- 线性模型泛化的可靠性是有代价的,因为线性模型没有考虑到特征之间的交互作用,由此模型灵活性受限。
- 泛化性和灵活性之间的基本权衡被描述为偏差-方差权衡。
- 线性模型有很高的偏差,因此它们只能表示一小类函数,但其方差很低,因此它们在不同的随机数据样本上可以得出相似的结果。
- 神经网络不局限于单独查看每个特征,而是学习特征之间的交互,但即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。
- 经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。 简单性以较小维度的形式展现,简单性的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。
- 暂退法在前向传播过程中,计算每一内部层的同时注入噪声。 因为当训练一个有多层的深层网络时,注入噪声只会在输入-输出映射上增强平滑性。从表面上看是在训练过程中丢弃(drop out)一些神经元。 在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
- 神经网络过拟合与每一层都依赖于前一层激活值相关,这种情况称为共适应性,而暂退法会破坏共适应性。
- 可以以一种无偏向的方式注入噪声,在固定住其他层时,每一层的期望值等于没有噪音时的值。
- 标准暂退正则化通过按未丢弃的节点的分数进行规范化来消除每一层的偏差,换言之,每个中间活性值
h
h
h以暂退概率
p
p
p由随机变量
h
′
h'
h′替换,即:
h ′ = { 0 概率为 p h 1 − p 其他情况 \begin{aligned} h' = \begin{cases} 0 & \text{ 概率为 } p \\ \frac{h}{1-p} & \text{ 其他情况} \end{cases} \end{aligned} h′={01−ph 概率为 p 其他情况 - 通常,我们在测试时不用暂退法。 给定一个训练好的模型和一个新的样本,我们不会丢弃任何节点,因此不需要标准化。 然而也有一些例外:一些研究人员在测试时使用暂退法, 用于估计神经网络预测的不确定性: 如果通过许多不同的暂退法遮盖后得到的预测结果都是一致的,那么我们可以说网络发挥更稳定。
- 我们可以将暂退法应用于每个隐藏层的输出(在激活函数之后), 并且可以为每一层分别设置暂退概率,常见的技巧是在靠近输入层的地方设置较低的暂退概率。
2. 实例解析
2.1. 实例描述
使用具有两个隐藏层的多层感知机和暂退法,拟合Fashion-MNIST数据集。
2.2. 代码实现
2.2.1. 主要代码
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.2), # 暂退概率为0.2
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(0.5), # 暂退概率为0.5
nn.Linear(256, 10)
).to(device)
2.2.2. 完整代码
import os
from tensorboardX import SummaryWriter
from rich.progress import track
from torchvision.transforms import Compose, ToTensor
from torchvision.datasets import FashionMNIST
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
def load_dataset():
"""加载数据集"""
root = "./dataset"
transform = Compose([ToTensor()])
mnist_train = FashionMNIST(root, True, transform, download=True)
mnist_test = FashionMNIST(root, False, transform, download=True)
dataloader_train = DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=num_workers,
)
dataloader_test = DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=num_workers,
)
return dataloader_train, dataloader_test
if __name__ == '__main__':
# 全局参数设置
num_epochs = 10
batch_size = 256
num_workers = 3
device = torch.device('cuda:0')
lr = 0.5
# 创建记录器
def log_dir():
root = "runs"
if not os.path.exists(root):
os.mkdir(root)
order = len(os.listdir(root)) + 1
return f'{root}/exp{order}'
writer = SummaryWriter(log_dir=log_dir())
# 数据集配置
dataloader_train, dataloader_test = load_dataset()
# 定义模型
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 10)
).to(device)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
criterion = nn.CrossEntropyLoss(reduction='none')
optimizer = optim.SGD(net.parameters(), lr=lr)
# 训练循环
for epoch in track(range(num_epochs), description='dropout'):
for X, y in dataloader_train:
X, y = X.to(device), y.to(device)
loss = criterion(net(X), y)
optimizer.zero_grad()
loss.mean().backward()
optimizer.step()
with torch.no_grad():
train_loss, train_acc, num_samples = 0.0, 0.0, 0
for X, y in dataloader_train:
X, y = X.to(device), y.to(device)
y_hat = net(X)
loss = criterion(y_hat, y)
train_loss += loss.sum()
train_acc += (y_hat.argmax(dim=1) == y).sum()
num_samples += y.numel()
train_loss /= num_samples
train_acc /= num_samples
test_acc, num_samples = 0.0, 0
for X, y in dataloader_test:
X, y = X.to(device), y.to(device)
y_hat = net(X)
test_acc += (y_hat.argmax(dim=1) == y).sum()
num_samples += y.numel()
test_acc /= num_samples
writer.add_scalars('metrics', {
'train_loss': train_loss,
'train_acc': train_acc,
'test_acc': test_acc
}, epoch)
writer.close()
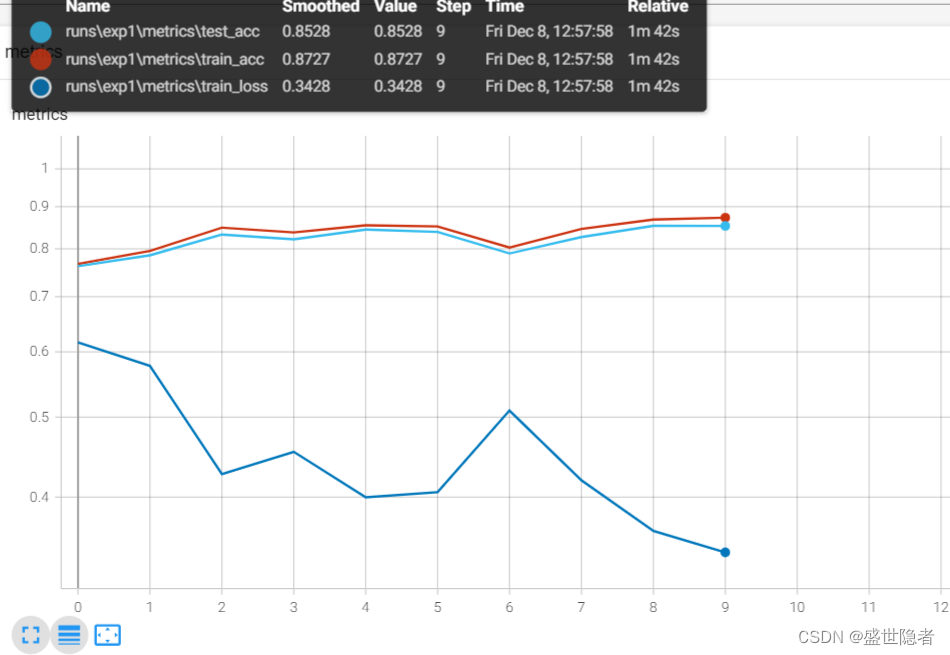
2.2.3. 输出结果