你写的C语言代码被翻译成可执行程序,需要这几步
本篇博客会讲解C语言的灵魂知识点:你写出来的C语言代码究竟是如何让计算机识别并且执行的。C语言是一门计算机语言,可以方便程序员和计算机沟通,但是,计算机只认得二进制,怎么会认得你写的C语言代码是什么意思呢?
确实,计算机只认识二进制,但是你写的C语言代码也会经过一些列的步骤,从而被翻译成计算机可以识别的二进制语言,也就是机器语言。把C语言翻译成机器语言的过程就是翻译过程。经过翻译后,C语言代码就被转化为可执行程序,就可以运行了,这个过程就是运行过程。翻译过程依赖的环境就是翻译环境,运行过程依赖的环境就是运行环境。任何C语言代码,想要被计算机识别,都必须依赖这两个环境。
运行环境很好理解,当C语言被翻译成二进制语言时,就产生了一个可执行程序,当这个程序被加载到内存中后,操作系统就会为其开辟栈空间(存储局部变量等)以及静态空间(存储全局变量和静态变量等),并分配对应的堆空间,用于动态内存管理。这些都是学习C语言时应该掌握的知识点。
本篇文章重点讨论的是翻译环境。翻译环境会涉及到编译器和链接器,分别用于编译和链接。C语言代码写的文件,后缀一般是.c,我们称这样的文件为源文件。源文件经过编译、链接后,会转换成可执行程序,这个过程就是翻译过程。而编译这个过程中,又分为3个阶段,分别是预编译(也称为预处理)、编译、汇编。
上面的讲解可能有点抽象,我画了一张图方便理解。
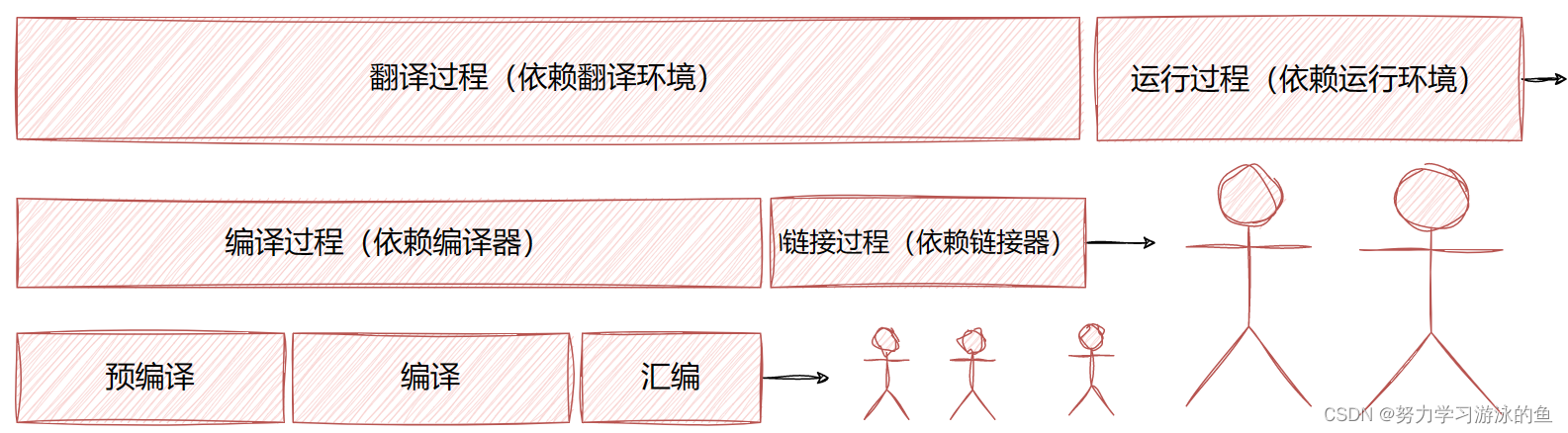
注意:编译过程是针对每个单独的源文件。也就是说,假设有3个源文件,test1.c, test2.c, test3.c,那么test1.c会被单独编译,test2.c也会单独编译,同理,test3.c也会单独编译,两两之间互不干扰。
1.编译过程
1.1 预编译
编译过程的第1个小步骤是预编译,主要完成的是文本处理。一个源文件(里面都是C语言代码)经过预编译之后,里面还是C语言代码。预编译主要完成的事情有:
- 删除注释。
- 头文件包含。
- #define的宏的替换。
- 条件编译。
- ……
这里主要讲解前3点,其他点我会专门写一篇博客,主要讲解预编译过程。
删除注释很好理解,这些注释是给人看的,对于计算机来说并没有用,所以会删掉。
头文件包含,比如写#include <stdio.h>就会被stdio.h这个头文件中的内容替换掉。当然不是一股脑全部替换掉,这里面还涉及到一些条件编译等等,会根据具体情况来处理。
#define的宏也会被替换掉。比如如果有#define NUM 100,那么代码中的所有NUM都会被替换成100。或者,#define MAX(x, y) ((x)>(y)?(x):(y)),MAX(3, 5)就会被替换成(3)>(5)?(3):(5),以此类推。
以上的操作都是文本处理,所以操作完后,文件中的代码还是C语言代码。经过预编译之后的文件,Linux下一般后缀是.i。
1.2 编译
编译过程的第2个小步骤,也称为编译,注意此编译非彼编译,这里的编译指的是编译过程的其中一个步骤。
一个源文件经过预处理之后,会进行编译。前面说过,预处理之后文件中仍然是C语言代码,而编译会把这些C语言代码翻译成汇编代码。这个过程主要完成下面4件事:
- 语法分析。
- 词法分析。
- 语义分析。
- 符号汇总。
其中,前3点如果展开会过于复杂,我会专门写一篇博客,讲解编译原理。
这里主要讲解第4点。编译会把代码中出现的全局性质的符号汇总起来,方便进一步处理。比如,有2个文件,分别是Test.c和Add.c。
// Test.c
extern int Add(int, int);
int main()
{
int a = 10;
int b = 20;
int sum = Add(a, b);
return 0;
}
// Add.c
int Add(int x, int y)
{
return x + y;
}
那么,Test.c经过预编译,编译之后,会被汇总的符号有Add, main;Add.c经过预编译,编译之后,会被汇总的符号有Add。注意,Add.c中的x, y,Test.c中的a, b, sum等都是一些局部的符号,是不会被汇总的。
在Linux下,编译之后形成的文件一般后缀为.s。
1.3 汇编
编译过程的第3个小步骤是汇编。汇编时,会把以上的汇编代码翻译成二进制指令。汇编的过程也很复杂,其中值得讲解的是,这个过程中做了一件很重要的事,形成了符号表。
前面提到,编译时进行了符号汇总,那么在汇编的过程中,就会根据汇总的符号,形成符号表。通俗来说,编译器会在这个表中为每一个符号填一个地址,这个地址有可能是有效的,也有可能是无效的。比如还是上面的Test.c和Add.c,他们分别进行了预编译、编译之后,都汇总了一些符号。由于main函数的定义就在Test.c中,所以Test.c的编译过程中就会给main填一个有效的地址(假设是0x100),而Add函数的定义不在Test.c中,所以Test.c的编译过程就会给Add填一个无效的地址(假设是0x000)。同理,Add.c的编译过程会给Add填一个有效的地址(假设是0x200)。这2个文件经过汇编之后分别形成一张符号表。
Test.c的符号表:
| main | Add |
|---|---|
| 0x100 | 0x000 |
Add.c的符号表:
| Add |
|---|
| 0x200 |
汇编结束后形成的文件,在Linux下后缀一般是.o。我们一般称这样的文件为目标可重定向二进制文件,简称目标文件。
2.链接过程
预编译、编译、汇编统称为编译过程,都是编译器完成的。编译过程结束后,会由链接器完成链接过程。编译过程只是单独处理每个文件,和编译过程不同,而链接过程会把前面编译过程形成的目标文件和一些库链接起来,是同时处理多个文件。链接过程主要做了下面2件事:
- 合并段表。
- 符号表的合并和重定向。
合并段表也是个很复杂的过程。由于前面形成的目标文件都是elf文件,是有格式的,会分成一个一个的段,而链接时,这些段会被分别合并到一起,最终形成的可执行程序也是elf文件。
这里重点讲解符号表的合并和重定向。前面提到,汇编过程中,每个.o文件都对应形成了一张符号表,那么链接过程就会把这几张表合并为一个新的符号表。合并的规则非常简单,每个符号都需要找到一个唯一对应的有效地址。比如,前面的Test.c和Add.c的例子中,Add符号只有一个有效的地址0x200,main符号只有一个有效的地址0x100。那么合并之后的符号表就是:
| main | Add |
|---|---|
| 0x100 | 0x200 |
这就能解释一些现象了。如果把Add.c中的Add函数整个删掉,合并符号表时,Add符号就找不到一个有效的地址了,就会报链接错误。
而编译过程和链接过程合起来就是翻译过程。用C语言写的源文件,经过翻译过程就形成了可执行程序,就能够被计算机识别并且执行了。
使用gcc完成以上步骤
假设有2个源文件,分别是Test.c和Add.c。
预编译,分别形成Test.i和Add.i。
gcc -E Test.c -o Test.i
gcc -E Add.c -o Add.i
编译,分别形成Test.s和Add.s。
gcc -S Test.i -o Test.s
gcc -S Add.i -o Add.s
汇编,分别形成Test.o和Add.o。
gcc -c Test.s -o Test.o
gcc -c Add.s -o Add.o
链接,形成Proc可执行程序。
gcc Test.o Add.o -o Proc
运行Proc。
./Proc
记忆方式:ESc, iso。其中,ESc就是键盘左上角的esc键(注意大小写不要搞错了)。iso也就是镜像文件,装过系统的朋友应该知道。不知道的就记成ios就行了,这个总知道吧。
总结
- 每个C源程序都会单独经过编译器,进行编译过程,形成多个目标文件,接着由链接器进行链接过程,把多个目标文件和一些库链接起来,形成可执行程序,就可以被计算机识别并且执行了。其中编译过程和链接过程合称翻译过程,执行的过程被称为运行过程。翻译依赖的环境(编译器和链接器)被称为翻译环境,执行依赖的环境被称为运行环境。
- 编译过程分为3个小阶段,分别是:预编译,编译,汇编。
- 预编译主要进行文本操作,该过程结束后,文件内部仍然是C语言代码。
- 编译会把C语言代码翻译成汇编代码。这个过程中主要的行为是:语法分析、词法分析、语义分析和符号汇总。
- 汇编会把汇编代码翻译成二进制代码,形成目标文件。这个过程中,主要的行为是形成符号表。
- 链接过程中,会把多个目标文件,和一些库,链接形成可执行程序。这个过程中,主要的行为是:合并段表,以及符号表的合并和重定向。
- 命令行:ESc, iso。
感谢大家的阅读!