redis问题归纳
1.redis为什么这么快?
(1)基于内存操作:redis的所有数据都存在内存中,因此所有的运算都是内存级别的,所以性能比较高
(2)数据结构简单:redis的数据结构是专门设计的,而这些简单的数据结构的查找和操作时间大部分复杂度都是O(1),因此性能比较高
(3)多路复用和非阻塞I/O:redis使用I/O多路复用功能来监听多个socket连接客户端,这样可以使用一个线程连接来处理多个请求
(4)避免上下文切换:单线程模型避免了不必要的上下文切换和多线程竞争,省去了多线程切换带来的时间和性能消耗
2.redis主要的性能瓶颈是内存或者网络带宽而非CPU
3.redis多线程的使用
网络硬件的性能提升,redis的性能瓶颈出现在网络IO的处理上,单个主线程处理网络请求的速度跟不上底层网络硬件的速度,所以redis6/7采用多个IO线程来处理网络请求,提高网络请求的并行度。redis的多IO只是用来处理网络请求的,对于读写操作命令redis仍然使用单线程,这样就避免了开发多线程的互斥加锁机制
4.面试问题
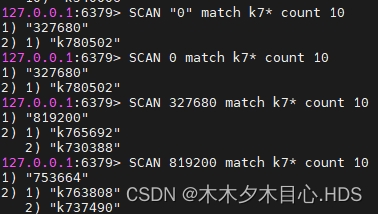
(1)海量数据里查询某一固定前缀key
scan命令遍历
(2)生产上如何限制keys */flushdb/flushall等危险命令以防止误删误用
key* 这个指令有致命的弊端,这个指令没有offset、limit参数,是要一次性遍历所有满足条件的key,由于redis是单线程的,其所有操作都是原子的,而keys算法是遍历算法,复杂度是O(n),如果实例中有千万级别以上的key,这个指令就会导致redis服务卡顿,所有读写redis的其它指令都会被延后甚至会超时报错,可能会引起缓存雪崩甚至数据库宕机。
禁用方法,在配置文件中:
rename-command keys ""
rename-command flushdb ""
rename-command flushall ""
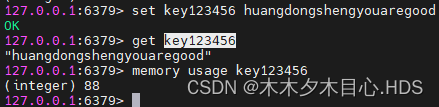
(3)memory usage 命令的使用
获取关键字的value所占内存的字节数
(4)bigkey多大算big?如何发现?如何删除?如何处理?
单个key的value小于10KB
对于集合类型的key,建议元素数量小于1000
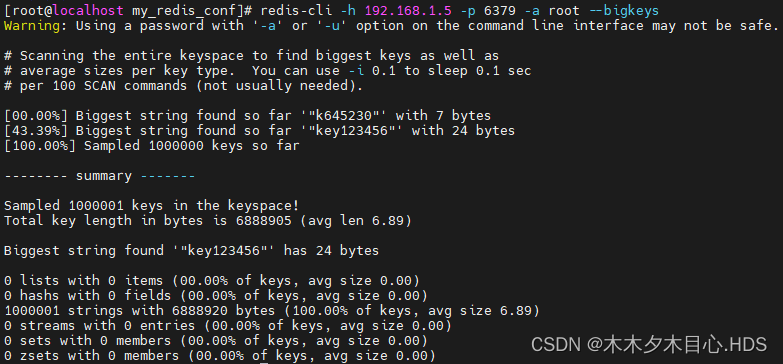
想查询大于10kb的所有key,--bigkeys参数就无能为力了,需要用到memory usage来计算每个键值的字节数
redis-cli -h 192.168.1.5 -p 6379 -a root --bigkeys
这个命令会扫描(Scan) Redis 中的所有 key ,会对 Redis 的性能有一点影响。并且,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 string 数据类型,包含元素最多的复合数据类型)
(5)bigkey做过调优吗?惰性释放lazyfree了解过吗?
使用lazyfree开启unlink命令和将del删除命令变为异步删除key,防止删除的时候卡顿
(6)生产上redis数据库有1000w记录,如何遍历?key * 可以吗?
不可以
scan遍历
SCAN "0" match k7* count 10
zscan 遍历 zset 集合元素
hscan 遍历 hash 字典的元素
sscan 遍历 set 集合的元素。

5.生成100万redis数据
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> ./redisTest.txt ;done;
cat ./redisTest.txt | redis-cli -h 192.168.1.5 -p 6379 -a root --pipe